OPICS Multiprocessing
Contents
OPICS Multiprocessing¶
OPICS support multiprocessing for faster simulations when working with large circuits.
import multiprocessing as mp
import opics as op
import numpy as np
import pandas as pd
import time
____ ____ _______________
/ __ \/ __ \/ _/ ____/ ___/
/ / / / /_/ // // / \__ \
/ /_/ / ____// // /___ ___/ /
\____/_/ /___/\____//____/
OPICS version 0.3.1
Enabling multiprocessing¶
Option 1: Using mp_config¶
OPICS multiprocessing can be enabled using the mp_config argument in opics.Network module.
circuit = op.Network(network_id="MRR_arr", mp_config={"enabled": True, "proc_count": 0, "close_pool": True})
OPICS multiprocessing is enabled.
Option 2: Using enable_mp¶
OPICS multiprocessing can also be enabled by calling the enable_mp function in opics.Network module.
circuit = op.Network(network_id = "MRR_arr")
circuit.enable_mp( process_count = 0,
close_pool = True)
OPICS multiprocessing is enabled.
Disable multiprocessing¶
OPICS multiprocessing can be disabled by calling the disable_mp function.
circuit.disable_mp()
OPICS multiprocessing is disabled.
Example: Multiple ring resonators coupled to a waveguide¶
In order to see how multiprocessing can help speed-up simulations, let’s create a circuit with n number of ring resonators coupled to a waveguide.
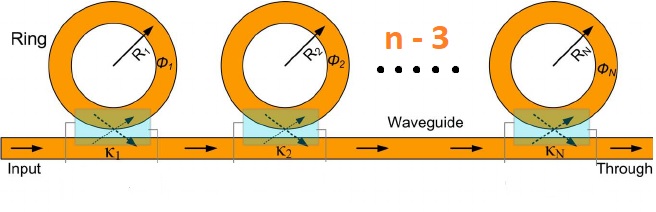
Without multiprocessing
We will be using bulk_add_component to add multiple components to the network.
components = op.libraries.ebeam
from opics.network import bulk_add_component
timer_start = time.perf_counter()
circuit = op.Network()
n_rings = 1500
_components_data = []
for count in range(n_rings):
_components_data.append(
{"component": components.DC_halfring,
"params": {"f": circuit.f},
"component_id": f"dc_{count}"})
_components_data.append(
{"component": components.Waveguide,
"params": {"f": circuit.f, "length": np.pi * 5e-6},
"component_id": f"wg_{count}"})
bulk_add_component(circuit, _components_data)
circuit.add_component(components.GC, component_id="input")
circuit.add_component(components.GC, component_id="output")
# bulk connect
prev_comp = ""
for count in range(n_rings):
if count == 0:
circuit.connect("input", 1, f"dc_{count}", 0)
circuit.connect(f"dc_{count}", 1, f"wg_{count}", 0)
circuit.connect(f"wg_{count}", 1, f"dc_{count}", 3)
prev_comp = "dc_0"
elif count >= 1:
circuit.connect(prev_comp, 2, f"dc_{count}", 0)
circuit.connect(f"dc_{count}", 1, f"wg_{count}", 0)
circuit.connect(f"wg_{count}", 1, f"dc_{count}", 3)
prev_comp = f"dc_{count}"
circuit.connect(prev_comp, 2, "output", 1)
circuit.simulate_network()
timer_stop = time.perf_counter()
sim_time = timer_stop - timer_start
print(f"simulation finished in {sim_time} s")
simulation finished in 18.2628713 s
With multiprocessing enabled
timer_start = time.perf_counter()
circuit = op.Network()
circuit.enable_mp()
n_rings = 1500
_components_data = []
for count in range(n_rings):
_components_data.append(
{"component": components.DC_halfring,
"params": {"f": circuit.f},
"component_id": f"dc_{count}"})
_components_data.append(
{"component": components.Waveguide,
"params": {"f": circuit.f, "length": np.pi * 5e-6},
"component_id": f"wg_{count}"})
bulk_add_component(circuit, _components_data)
circuit.add_component(components.GC, component_id="input")
circuit.add_component(components.GC, component_id="output")
# bulk connect
prev_comp = ""
for count in range(n_rings):
if count == 0:
circuit.connect("input", 1, f"dc_{count}", 0)
circuit.connect(f"dc_{count}", 1, f"wg_{count}", 0)
circuit.connect(f"wg_{count}", 1, f"dc_{count}", 3)
prev_comp = "dc_0"
elif count >= 1:
circuit.connect(prev_comp, 2, f"dc_{count}", 0)
circuit.connect(f"dc_{count}", 1, f"wg_{count}", 0)
circuit.connect(f"wg_{count}", 1, f"dc_{count}", 3)
prev_comp = f"dc_{count}"
circuit.connect(prev_comp, 2, "output", 1)
circuit.simulate_network()
timer_stop = time.perf_counter()
sim_time = timer_stop - timer_start
print(f"simulation finished in {sim_time} s")
OPICS multiprocessing is enabled.
simulation finished in 14.118123099999998 s
With multiprocessing enabled, we can get speed-ups of upto 30-40%.
Here are multiprocessing results for different values of n on an AMD Ryzen 9 5900X 12-Core Processor.
df = pd.read_pickle("../_static/_data/mp_log_data.pkl")
df
| n_count | t_normal (s) | t_mp (s) | speed-up(%) | |
|---|---|---|---|---|
| 0 | 10 | 0.12 | 1.07 | -7.916667 |
| 1 | 100 | 1.09 | 1.59 | -0.458716 |
| 2 | 1000 | 11.58 | 8.08 | 0.302245 |
| 3 | 10000 | 221.40 | 140.95 | 0.363369 |
| 4 | 20000 | 693.65 | 409.24 | 0.410019 |
| 5 | 25000 | 1085.94 | 602.27 | 0.445393 |
For smaller circuits, there is a penalty for creating sub-processes. This is something to keep in mind when using OPICS multiprocessing. However, for large circuits, we observed speed-ups of up to 45%.